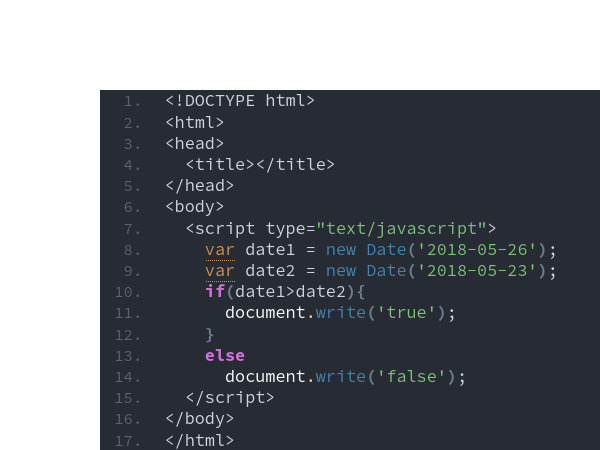
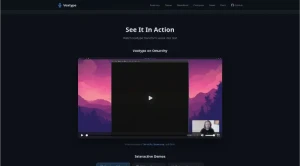
Push-to-talk voice-to-text that works on any desktop. Hold a key, speak, release. Your words appear at the cursor.
Voxtype is an open-source, push-to-talk voice-to-text application designed specifically for Linux and macOS. It allows users to dictate text directly into any application by holding a key, speaking, and then releasing the key to see their words appear at the cursor.
The principal functionalities of this tool include:
1. Controlled Dictation Workflow
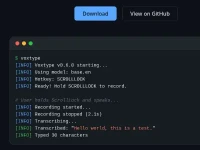
Push-to-Talk: A natural workflow where users hold a key to record and release it to transcribe. This method avoids "wake words" and accidental activations.
Smart Output: It types directly at the cursor via tools like
wtypeorydotool, featuring full CJK/Unicode support, and can fall back to the clipboard if needed.Highly Configurable: Users can choose their own hotkeys, output modes, and specific Whisper model sizes (from tiny to large-v3) to balance speed and accuracy.
2. Privacy and Performance
Fully Offline: All speech recognition happens locally on the user's machine using
whisper.cpp. No voice data is sent to the cloud, ensuring total privacy.GPU Acceleration: Built in Rust for high performance, it offers optional support for Vulkan, CUDA, Metal, and ROCm, enabling sub-second transcription on modern hardware.
Lightweight Design: It is distributed as a single binary with minimal dependencies, requiring no Python or complex virtual environments.
3. Native Desktop Integration
Wayland Optimized: It features native support for compositors like Hyprland, Sway, and River, allowing users to use native compositor keybindings without requiring a special input group. It also remains compatible with X11, GNOME, and KDE.
Visual Feedback: It includes optional Waybar integration with 10 built-in icon themes to show recording status, as well as desktop notifications via
notify-send.
4. Advanced Power Features
LLM Post-Processing: Transcriptions can be piped through local LLMs for tasks like translation, applying domain-specific vocabulary, or custom workflows.
Remote Offloading: Users can offload transcription tasks to a self-hosted remote GPU server to save resources on their local machine, though cloud API connections are also an option.
Multilingual Support: Beyond standard Whisper models, it supports various ONNX engines specialized for different languages and dialects, including Chinese, Japanese, and Korean.
You may also be interested in ...
How Do You Remove Unused CSS From a Site?
Making Tables Responsive With Minimal CSS